Draw the Abstract Syntax Trees for the Following Predicates
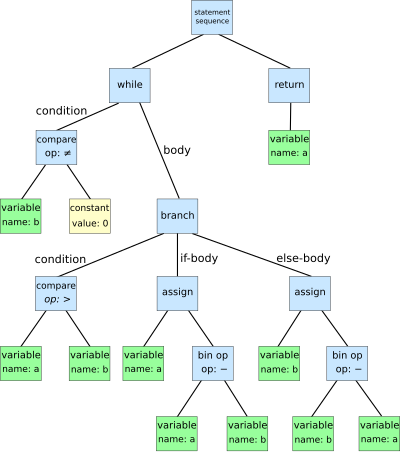
An abstract syntax tree for the following code for the Euclidean algorithm:
while b ≠ 0 : if a > b : a := a - b else : b := b - a return a In computer science, an abstract syntax tree (AST), or just syntax tree, is a tree representation of the abstract syntactic structure of text (often source code) written in a formal language. Each node of the tree denotes a construct occurring in the text.
The syntax is "abstract" in the sense that it does not represent every detail appearing in the real syntax, but rather just the structural or content-related details. For instance, grouping parentheses are implicit in the tree structure, so these do not have to be represented as separate nodes. Likewise, a syntactic construct like an if-condition-then statement may be denoted by means of a single node with three branches.
This distinguishes abstract syntax trees from concrete syntax trees, traditionally designated parse trees. Parse trees are typically built by a parser during the source code translation and compiling process. Once built, additional information is added to the AST by means of subsequent processing, e.g., contextual analysis.
Abstract syntax trees are also used in program analysis and program transformation systems.
Application in compilers [edit]
Abstract syntax trees are data structures widely used in compilers to represent the structure of program code. An AST is usually the result of the syntax analysis phase of a compiler. It often serves as an intermediate representation of the program through several stages that the compiler requires, and has a strong impact on the final output of the compiler.
Motivation [edit]
An AST has several properties that aid the further steps of the compilation process:
- An AST can be edited and enhanced with information such as properties and annotations for every element it contains. Such editing and annotation is impossible with the source code of a program, since it would imply changing it.
- Compared to the source code, an AST does not include inessential punctuation and delimiters (braces, semicolons, parentheses, etc.).
- An AST usually contains extra information about the program, due to the consecutive stages of analysis by the compiler. For example, it may store the position of each element in the source code, allowing the compiler to print useful error messages.
ASTs are needed because of the inherent nature of programming languages and their documentation. Languages are often ambiguous by nature. In order to avoid this ambiguity, programming languages are often specified as a context-free grammar (CFG). However, there are often aspects of programming languages that a CFG can't express, but are part of the language and are documented in its specification. These are details that require a context to determine their validity and behaviour. For example, if a language allows new types to be declared, a CFG cannot predict the names of such types nor the way in which they should be used. Even if a language has a predefined set of types, enforcing proper usage usually requires some context. Another example is duck typing, where the type of an element can change depending on context. Operator overloading is yet another case where correct usage and final function are context-dependent.
Design [edit]
The design of an AST is often closely linked with the design of a compiler and its expected features.
Core requirements include the following:
- Variable types must be preserved, as well as the location of each declaration in source code.
- The order of executable statements must be explicitly represented and well defined.
- Left and right components of binary operations must be stored and correctly identified.
- Identifiers and their assigned values must be stored for assignment statements.
These requirements can be used to design the data structure for the AST.
Some operations will always require two elements, such as the two terms for addition. However, some language constructs require an arbitrarily large number of children, such as argument lists passed to programs from the command shell. As a result, an AST used to represent code written in such a language has to also be flexible enough to allow for quick addition of an unknown quantity of children.
To support compiler verification it should be possible to unparse an AST into source code form. The source code produced should be sufficiently similar to the original in appearance and identical in execution, upon recompilation. The AST is used intensively during semantic analysis, where the compiler checks for correct usage of the elements of the program and the language. The compiler also generates symbol tables based on the AST during semantic analysis. A complete traversal of the tree allows verification of the correctness of the program.
After verifying correctness, the AST serves as the base for code generation. The AST is often used to generate an intermediate representation (IR), sometimes called an intermediate language, for the code generation.
Other usages [edit]
AST differencing [edit]
AST differencing, or for short tree differencing, consists of computing the list of differences between two ASTs.[1] This list of differences is typically called an edit script. The edit script directly refers to the AST of the code. For instance, an edit action may the addition of a new AST node representing a function. The problem of computing good AST edit scripts is hard, with two main challenges: handling move actions, and scaling to fine-grained ASTs with thousands of nodes.[2]
Structured merge [edit]
With proper AST differencing, ASTs can be used for merging versions and branches, this is known as structured merge. The advantage is to avoid spurious conflicts due to lines and formatting.[3]
Clone detection [edit]
An AST is a powerful abstraction to perform code clone detection.[4]
See also [edit]
- Abstract semantic graph (ASG), also called term graph
- Composite pattern
- Control-flow graph
- Directed acyclic graph (DAG)
- Document Object Model (DOM)
- Expression tree
- Extended Backus–Naur form
- Lisp, a family of languages written in trees, with macros to manipulate code trees
- Parse tree, also known as concrete syntax tree
- Semantic resolution tree (SRT)
- Shunting-yard algorithm
- Symbol table
- TreeDL
References [edit]
- ^ Fluri, Beat; Wursch, Michael; PInzger, Martin; Gall, Harald (2007). "Change Distilling:Tree Differencing for Fine-Grained Source Code Change Extraction". IEEE Transactions on Software Engineering. 33 (11): 725–743. doi:10.1109/tse.2007.70731. ISSN 0098-5589. S2CID 13659557.
- ^ Falleri, Jean-Rémy; Morandat, Floréal; Blanc, Xavier; Martinez, Matias; Monperrus, Martin (2014-09-15). "Fine-grained and accurate source code differencing". Proceedings of the 29th ACM/IEEE International Conference on Automated Software Engineering. Vasteras Sweden: ACM: 313–324. doi:10.1145/2642937.2642982. ISBN978-1-4503-3013-8. S2CID 218737160.
- ^ Larsen, Simon; Falleri, Jean-Remy; Baudry, Benoit; Monperrus, Martin (2022). "Spork: Structured Merge for Java with Formatting Preservation". IEEE Transactions on Software Engineering: 1. arXiv:2202.05329. doi:10.1109/TSE.2022.3143766. ISSN 0098-5589. S2CID 246823829.
- ^ Koschke, Rainer; Falke, Raimar; Frenzel, Pierre (2006). "Clone Detection Using Abstract Syntax Suffix Trees". 2006 13th Working Conference on Reverse Engineering. IEEE: 253–262. doi:10.1109/wcre.2006.18. ISBN0-7695-2719-1. S2CID 6985484.
Further reading [edit]
- Jones, Joel. "Abstract Syntax Tree Implementation Idioms" (PDF). (overview of AST implementation in various language families)
- Neamtiu, Iulian; Foster, Jeffrey S.; Hicks, Michael (May 17, 2005). Understanding Source Code Evolution Using Abstract Syntax Tree Matching. MSR'05. Saint Louis, Missouri: ACM. CiteSeerX10.1.1.88.5815.
- Würsch, Michael. Improving Abstract Syntax Tree based Source Code Change Detection (Diploma thesis).
- Lucas, Jason (16 August 2006). "Thoughts on the Visual C++ Abstract Syntax Tree (AST)".
External links [edit]
- AST View: an Eclipse plugin to visualize a Java abstract syntax tree
- "Abstract Syntax Tree and Java Code Manipulation in the Eclipse IDE". eclipse.org.
- "CAST representation". cs.utah.edu.
- eli project: Abstract Syntax Tree Unparsing
- "Abstract Syntax Tree Metamodel Standard" (PDF).
- "Architecture‑Driven Modernization — ADM: Abstract Syntax Tree Metamodeling — ASTM". (OMG standard).
- JavaParser: The JavaParser library provides you with an Abstract Syntax Tree of your Java code. The AST structure then allows you to work with your Java code in an easy programmatic way.
- Spoon: A library to analyze, transform, rewrite, and transpile Java source code. It parses source files to build a well-designed AST with powerful analysis and transformation API.
Source: https://en.wikipedia.org/wiki/Abstract_syntax_tree
0 Response to "Draw the Abstract Syntax Trees for the Following Predicates"
Enviar um comentário